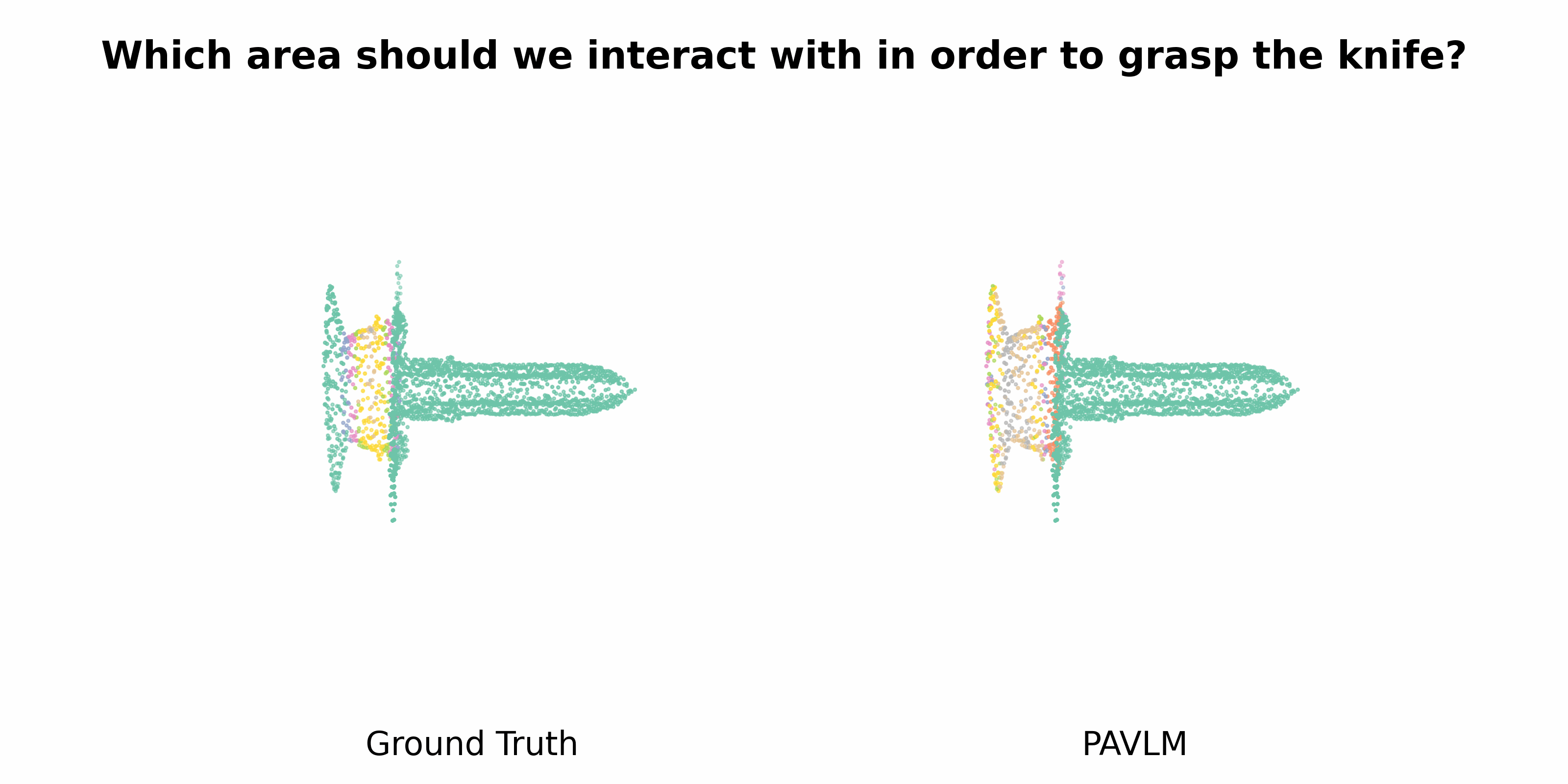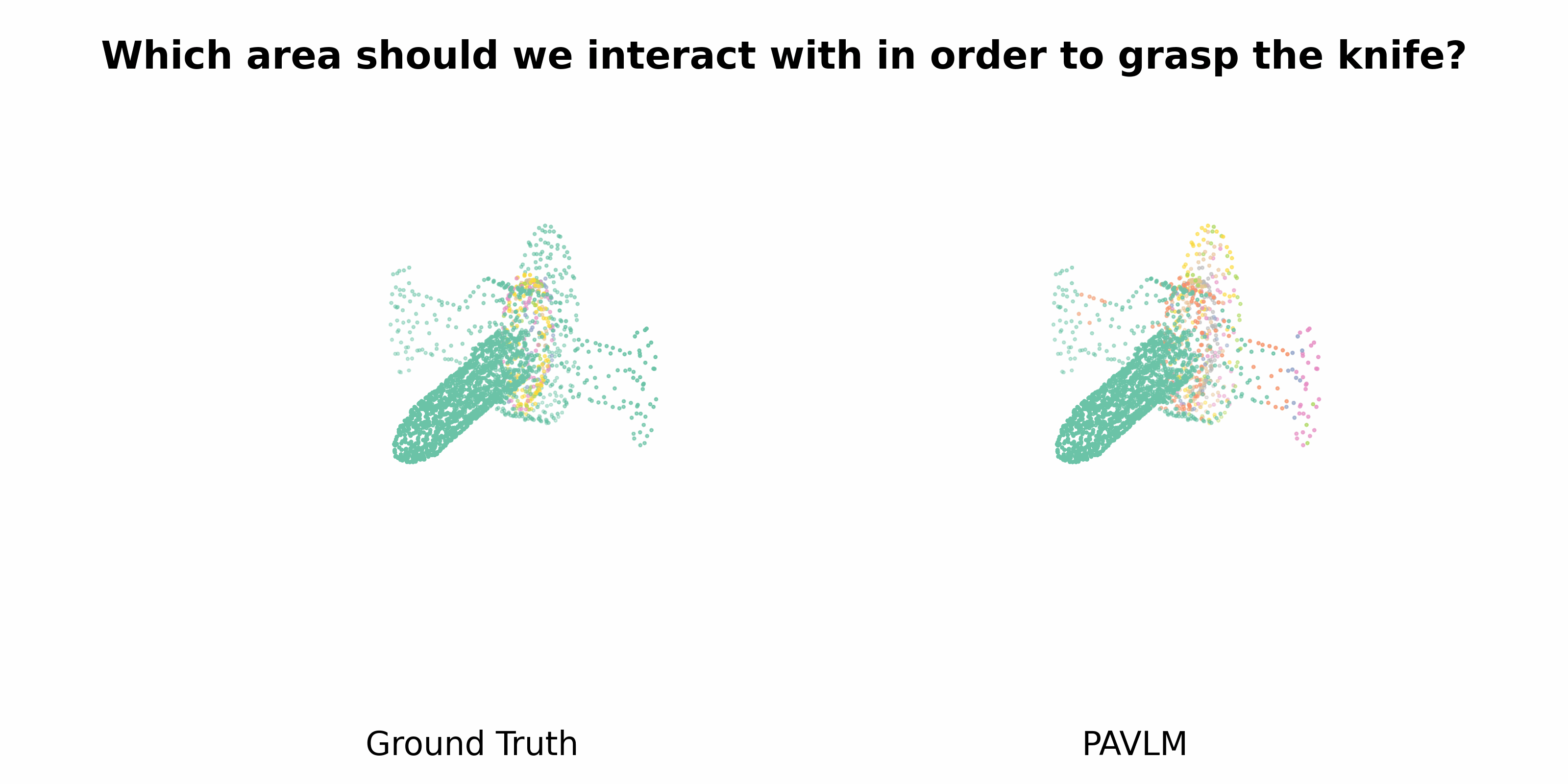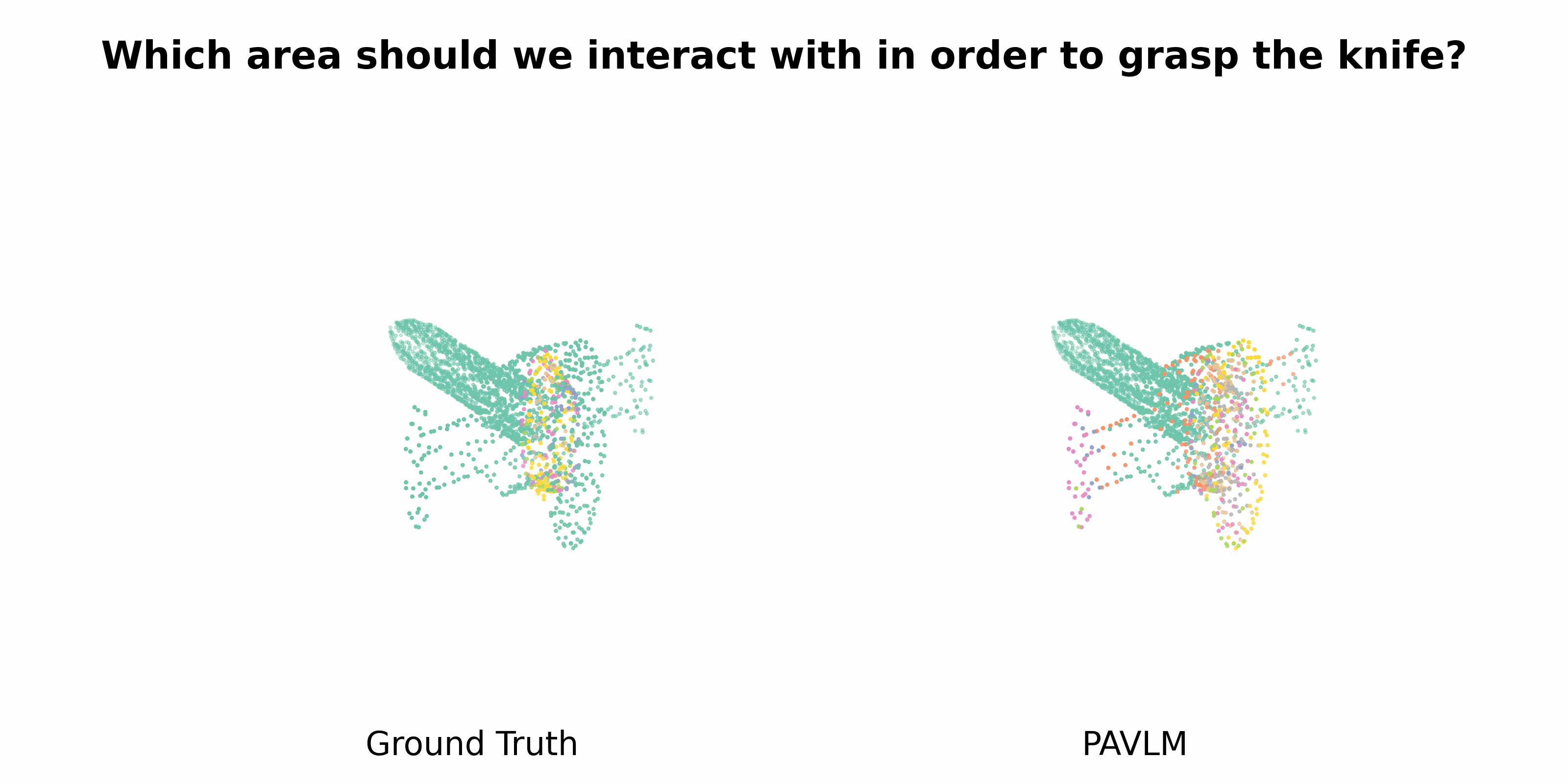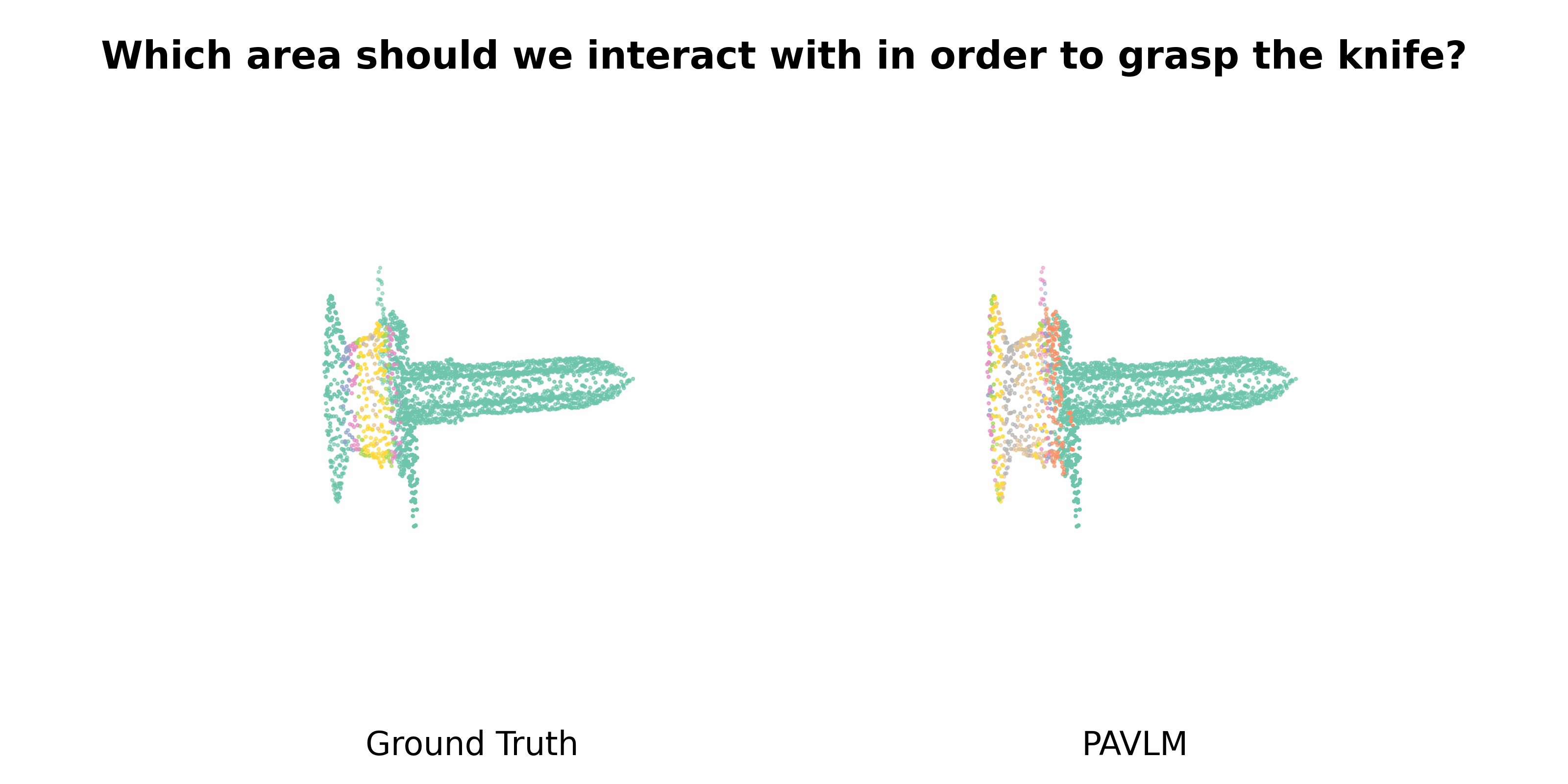
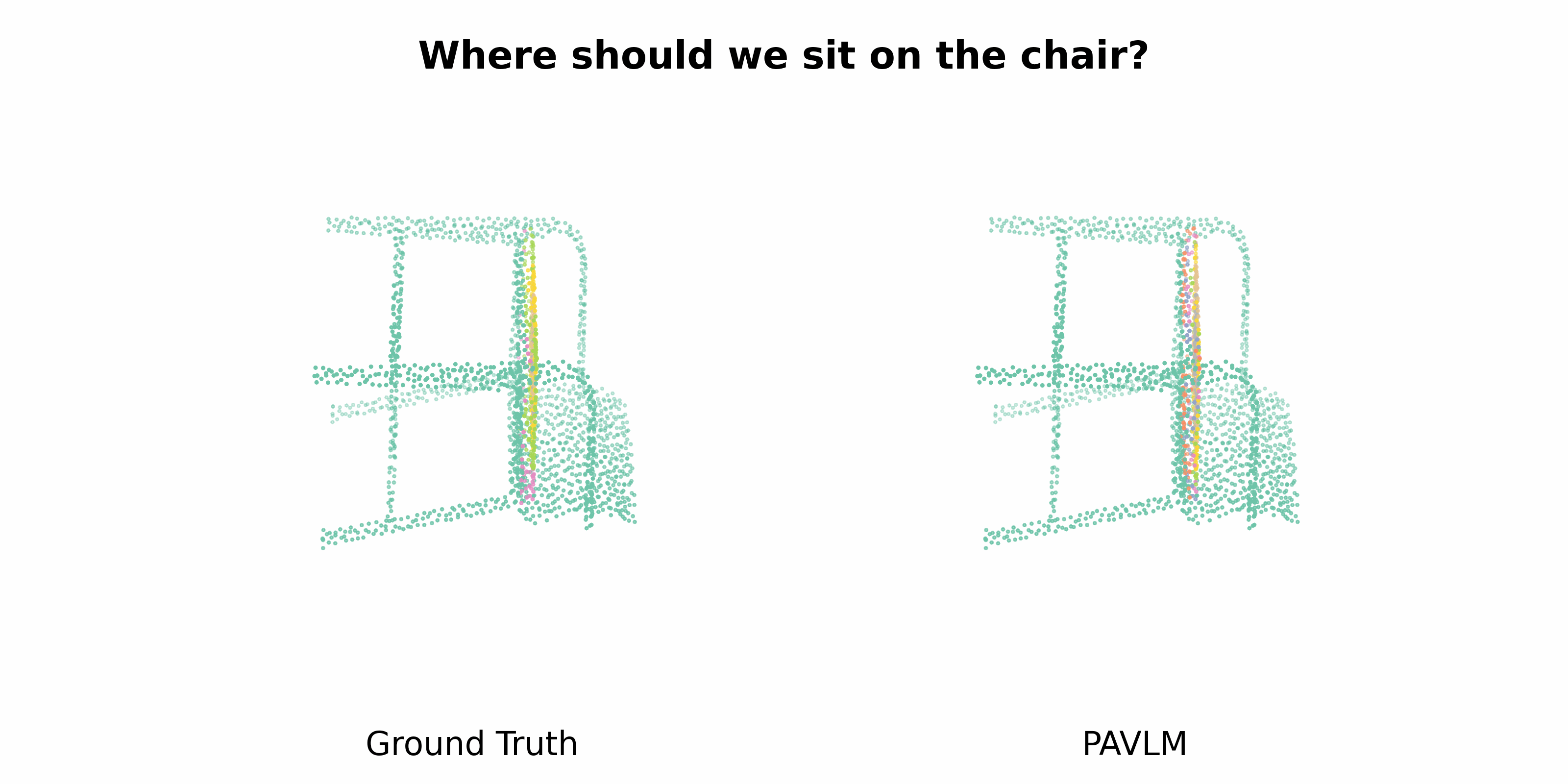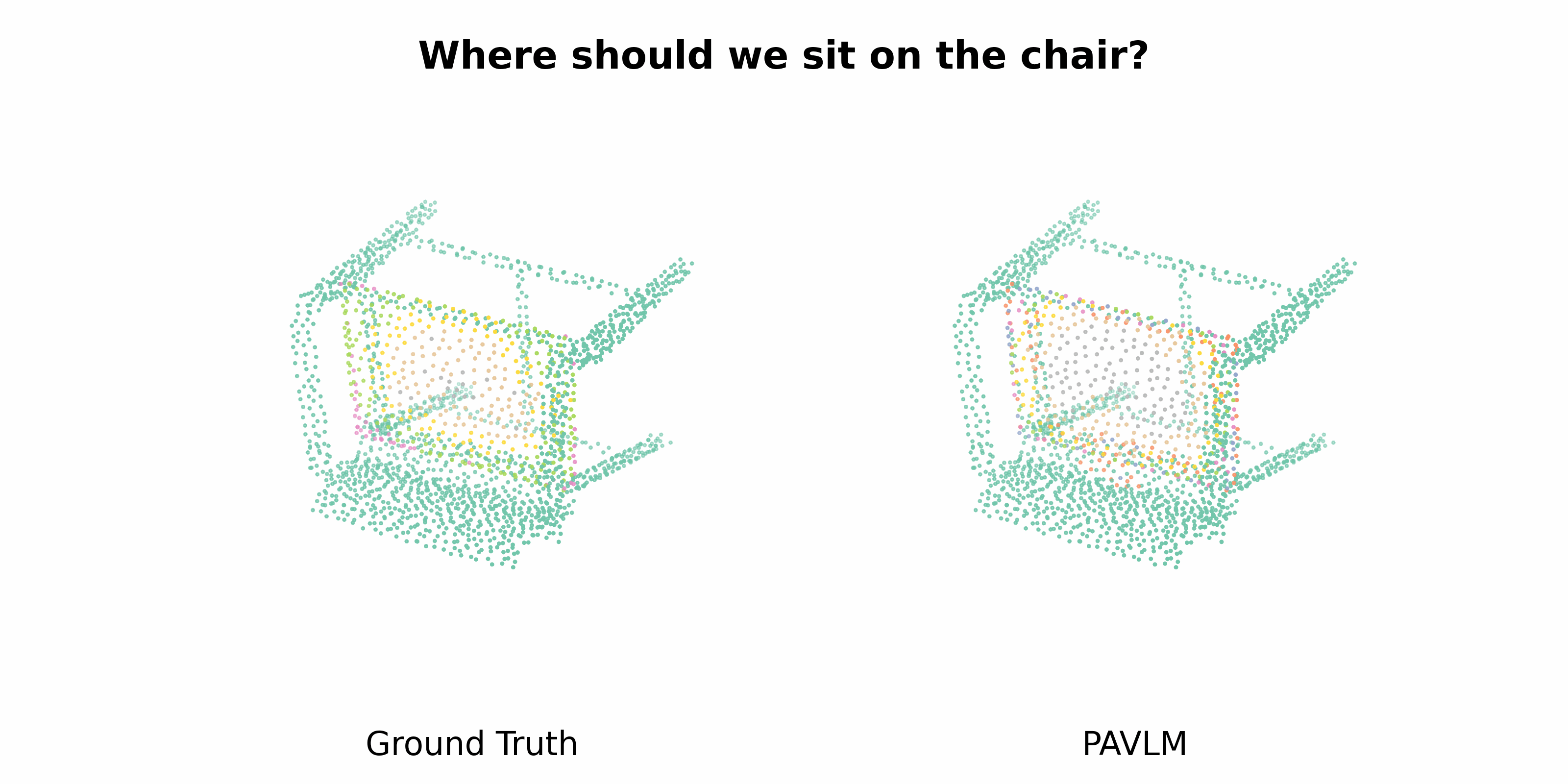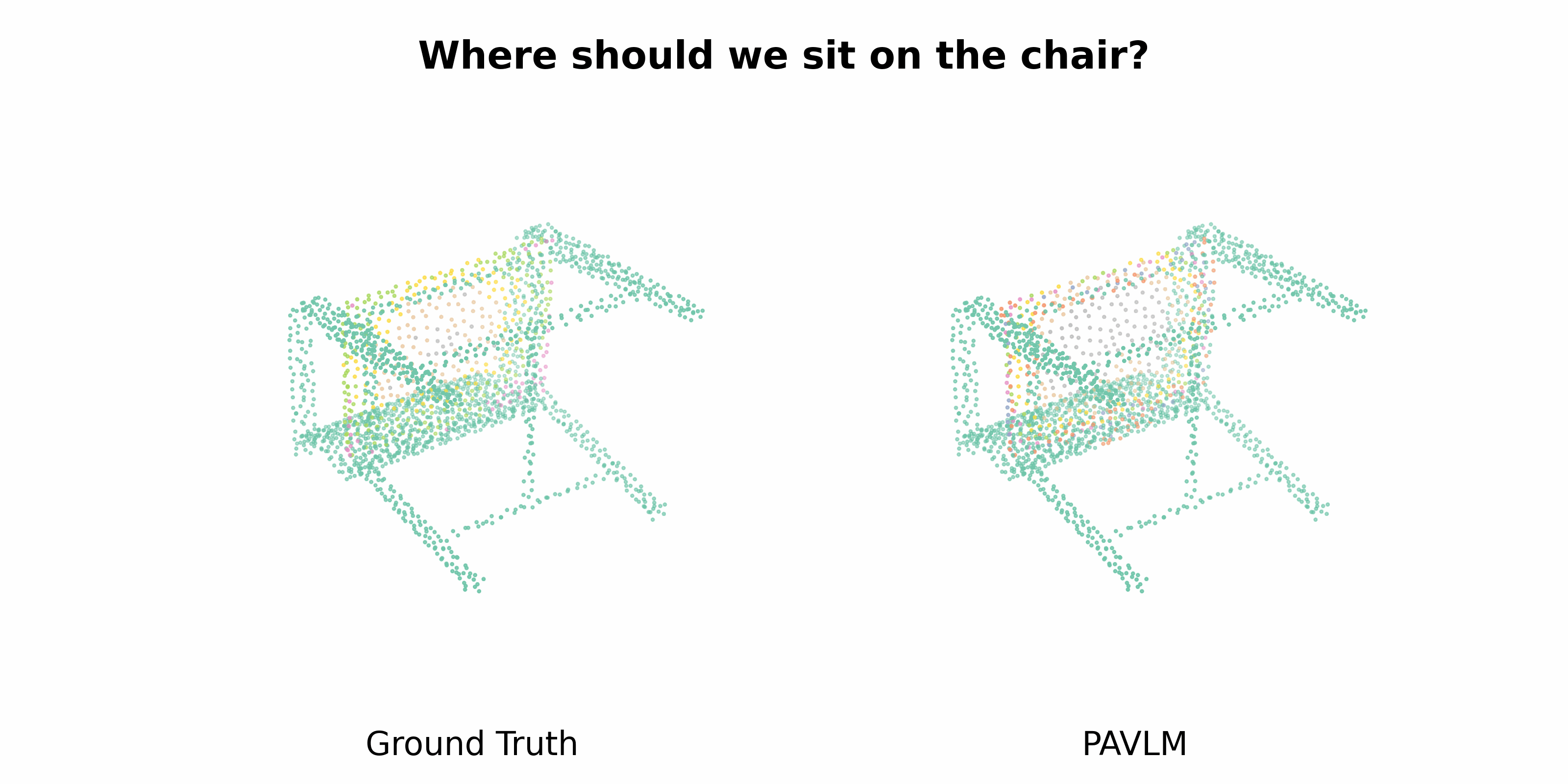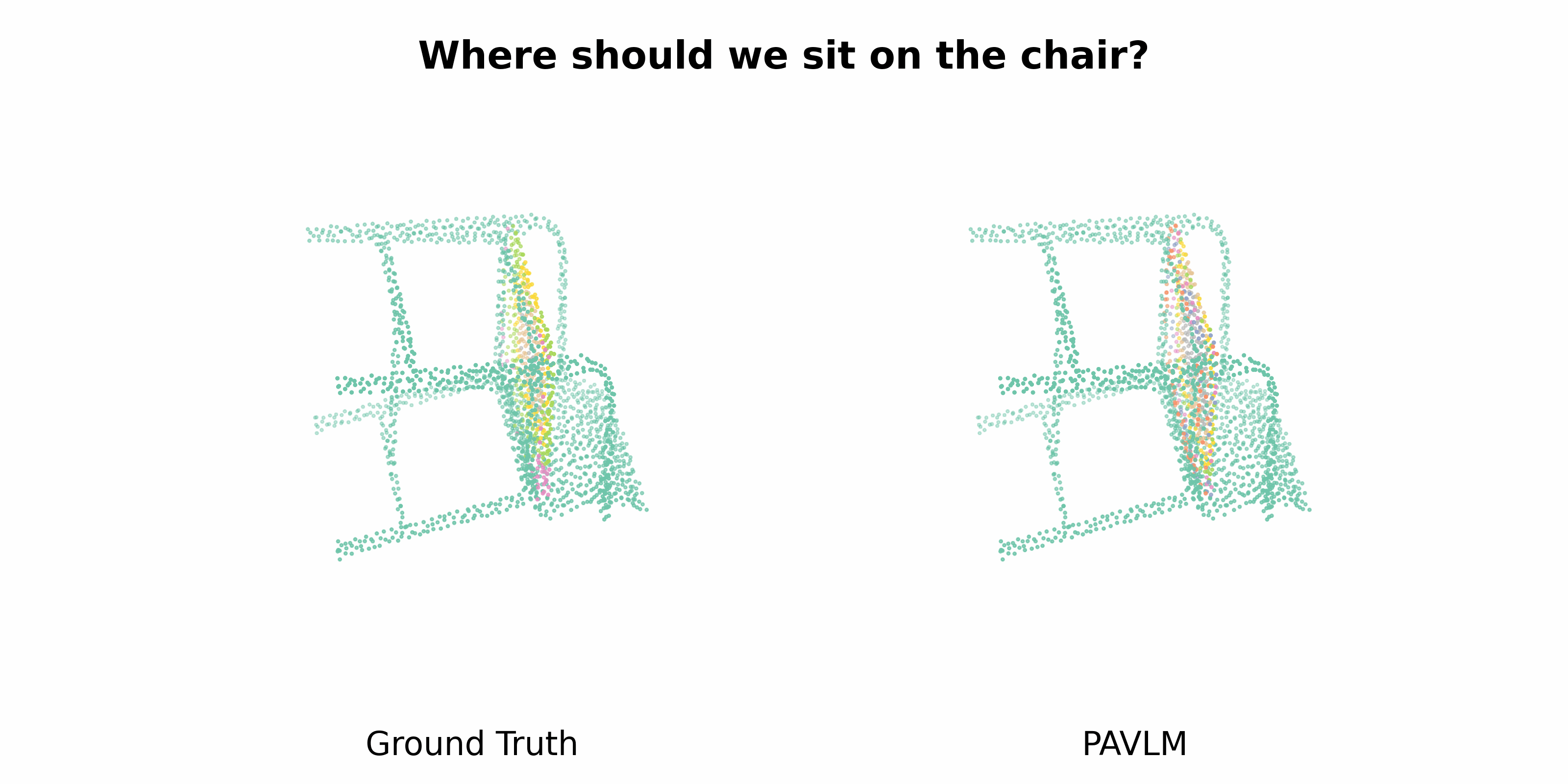
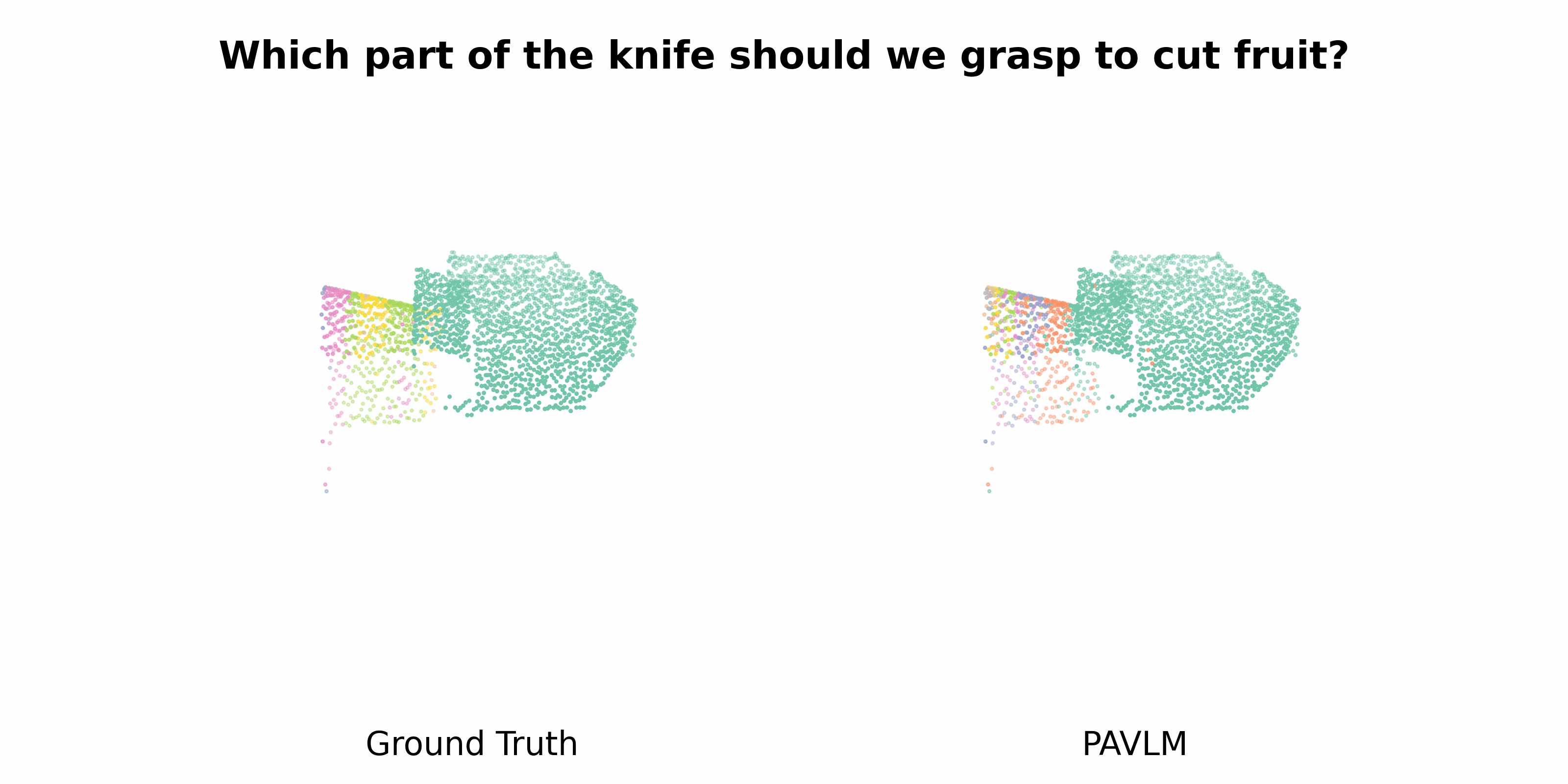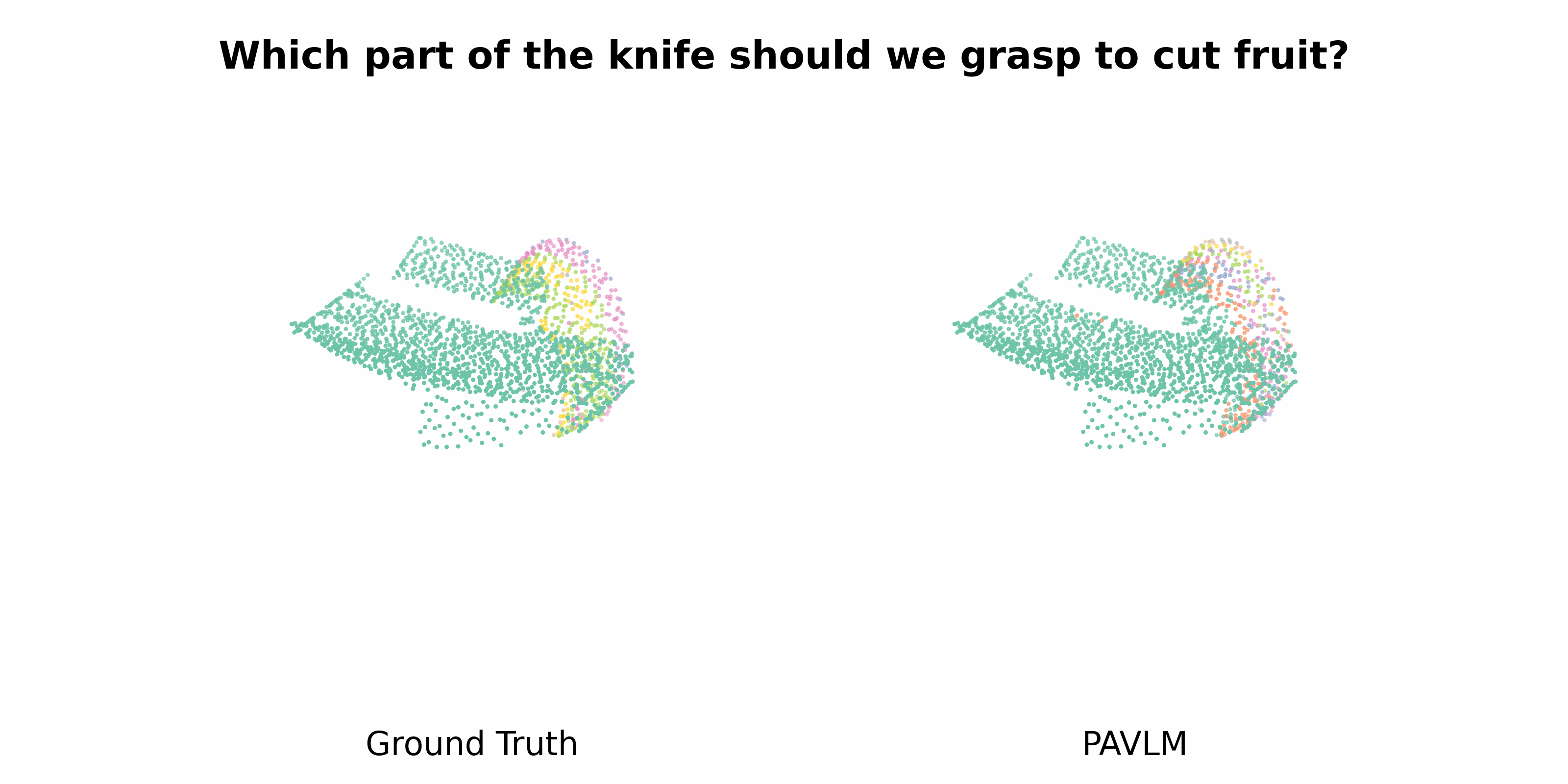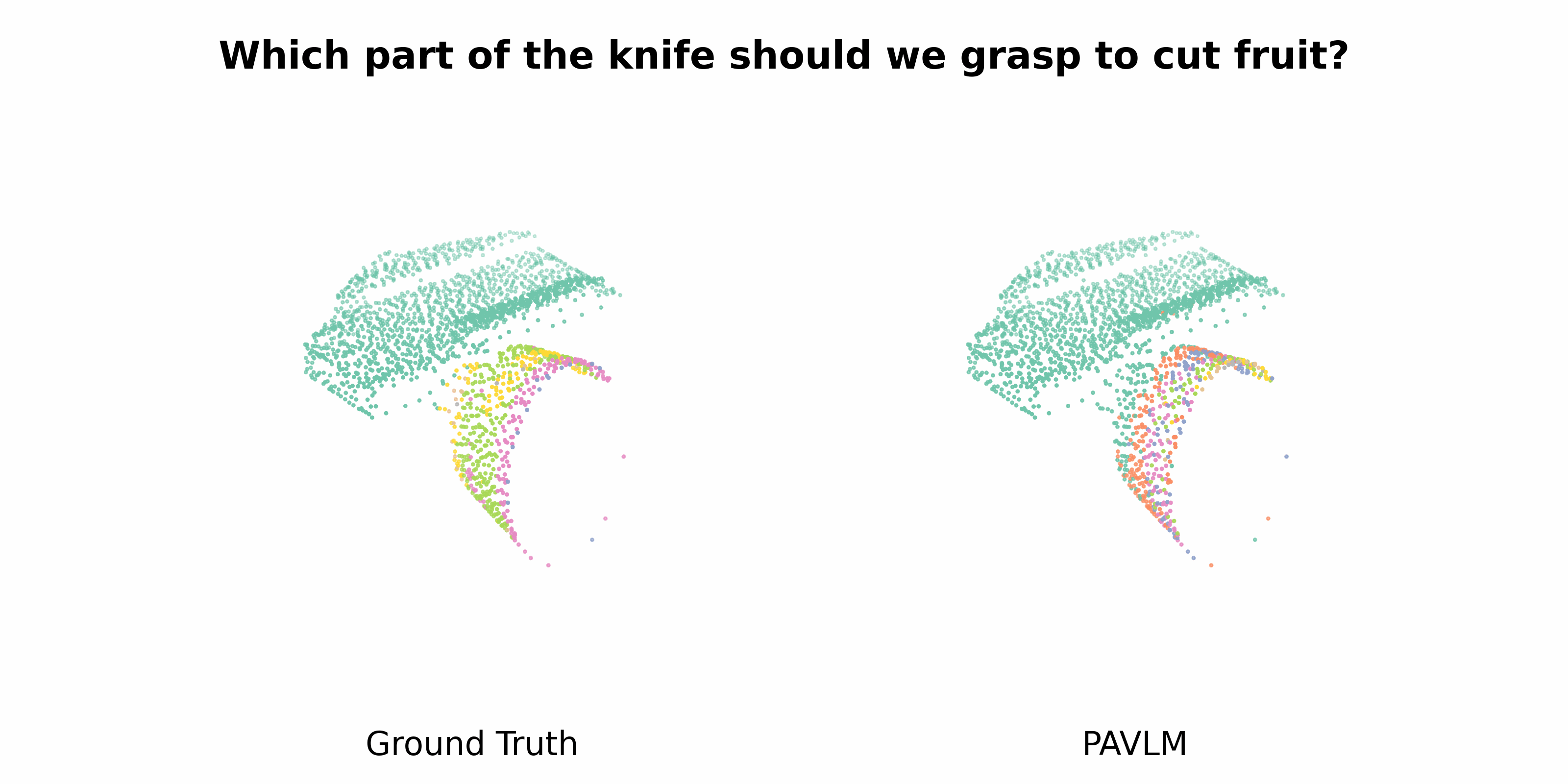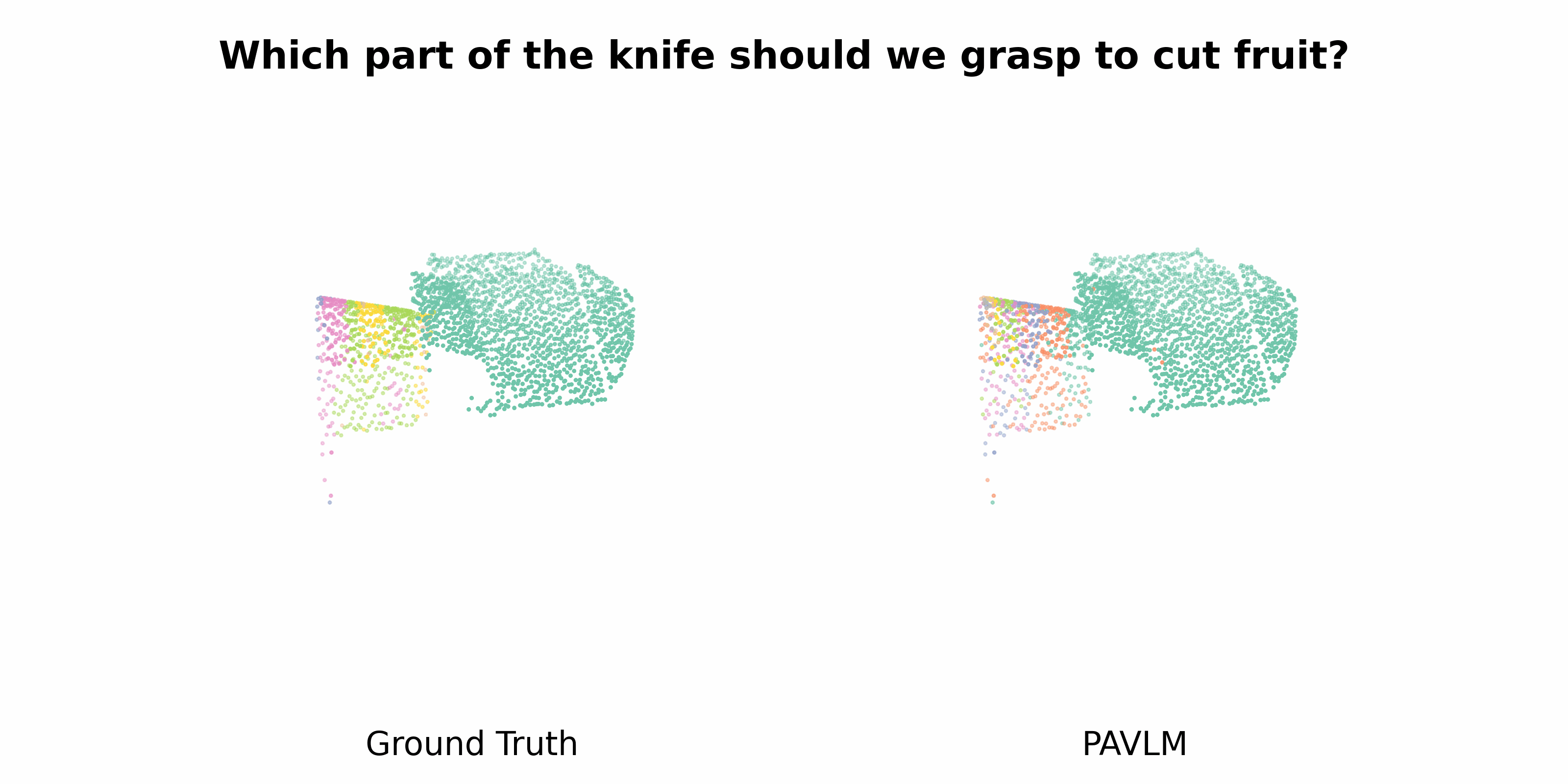
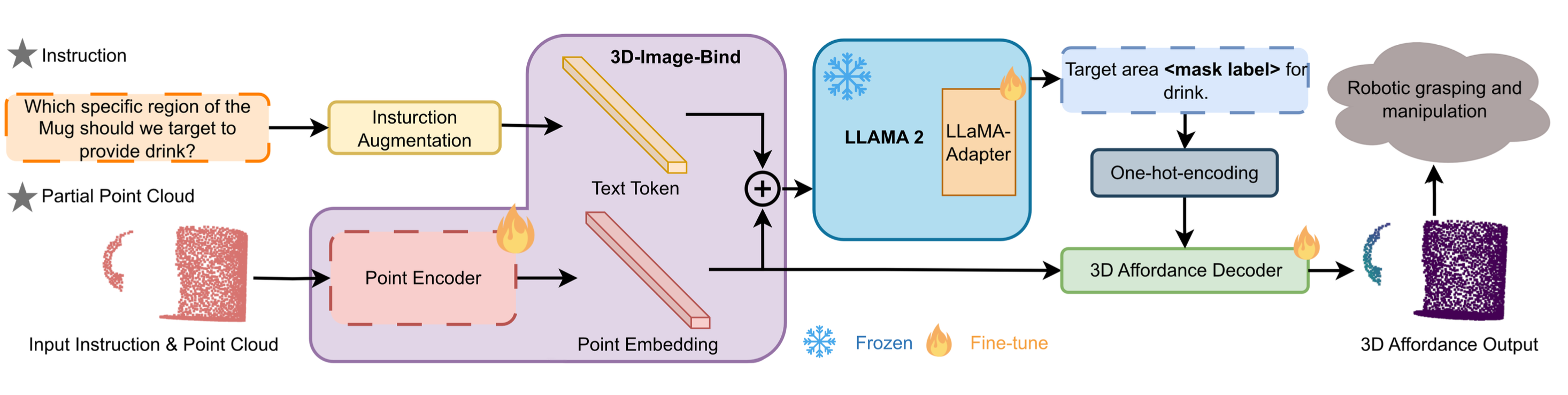
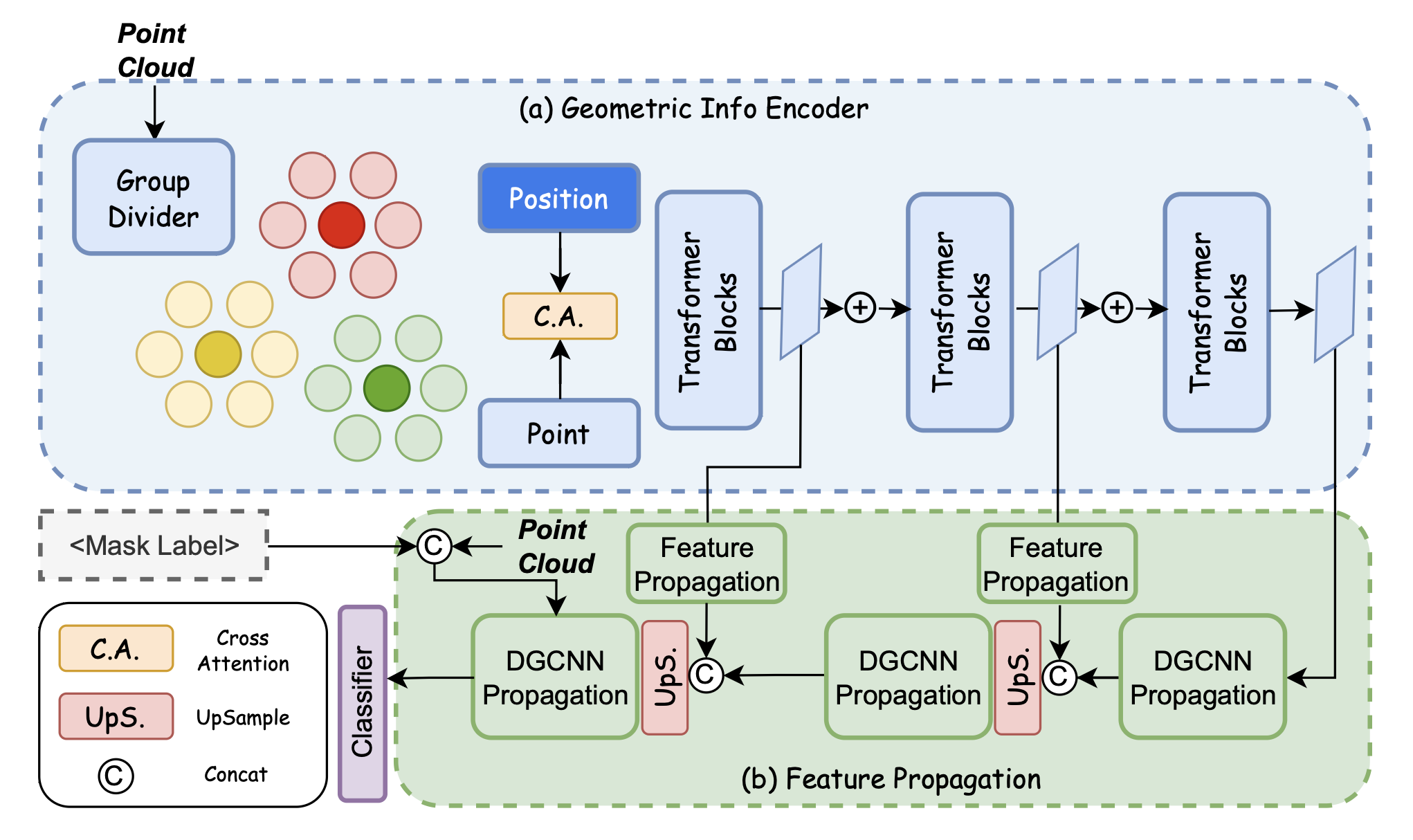
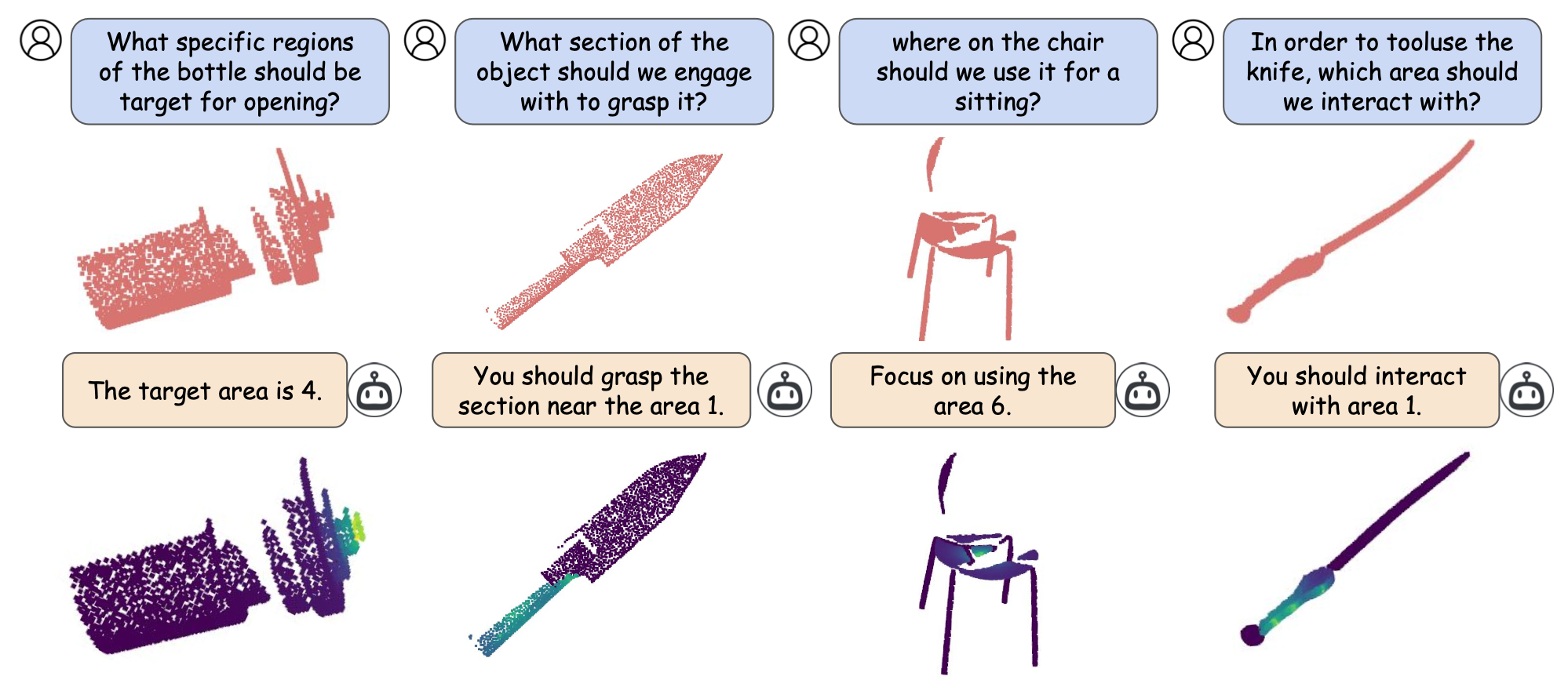
PAVLM combines the strengths of visual and language models to enhance 3D affordance understanding. Specifically, our geometric-guided propagation module enriches visual semantics, while LLaMa-3.1 generates refined, context-aware text instructions to better guide the robot's actions. In the following sections, we will delve into the architecture of the key components, starting with the Geometric-guided Point Encoder and Decoder. The diagram visually illustrates the overall architecture of PAVLM, highlighting the interaction between the visual and language models.